AI That Learns
Locally
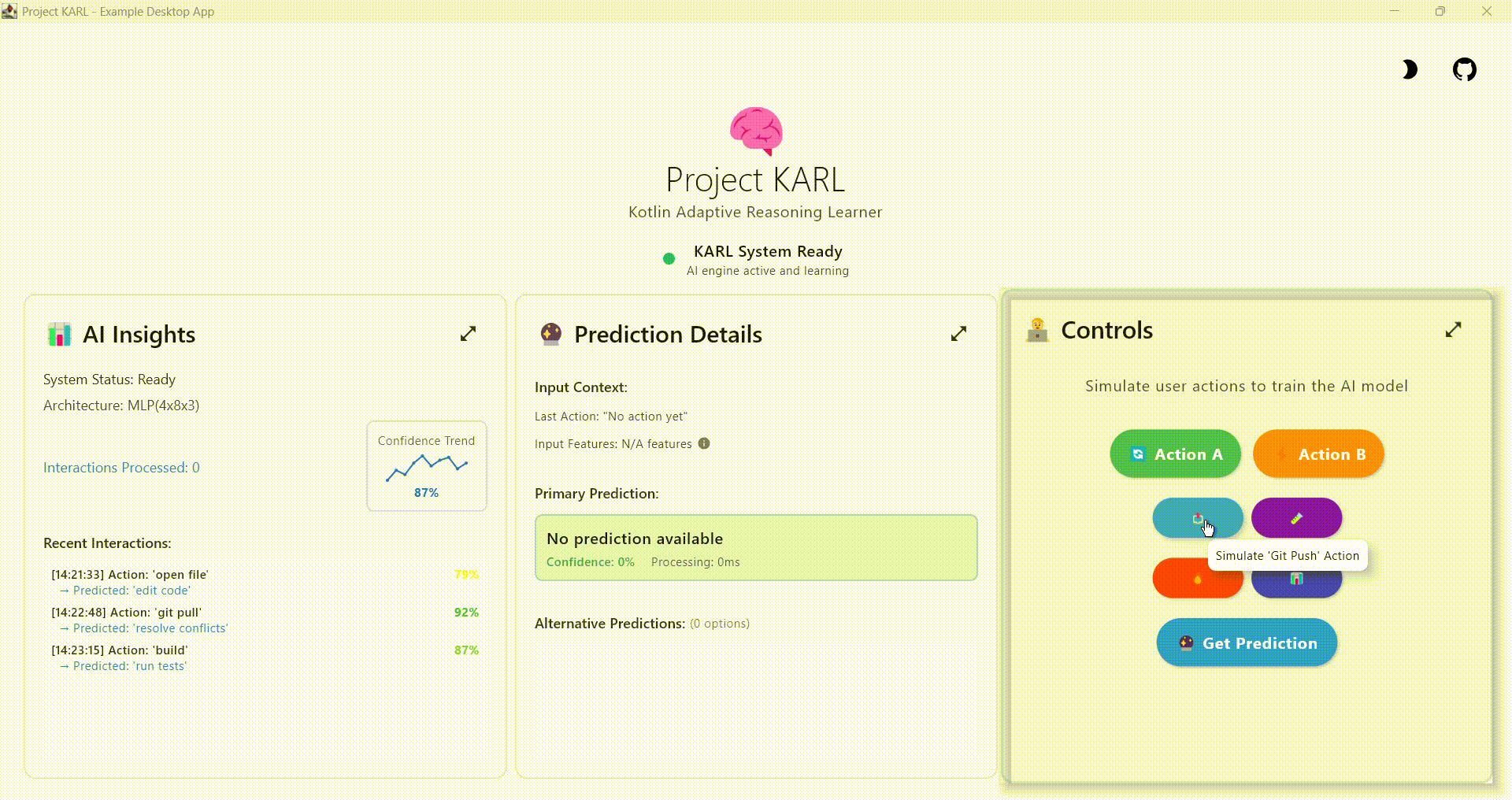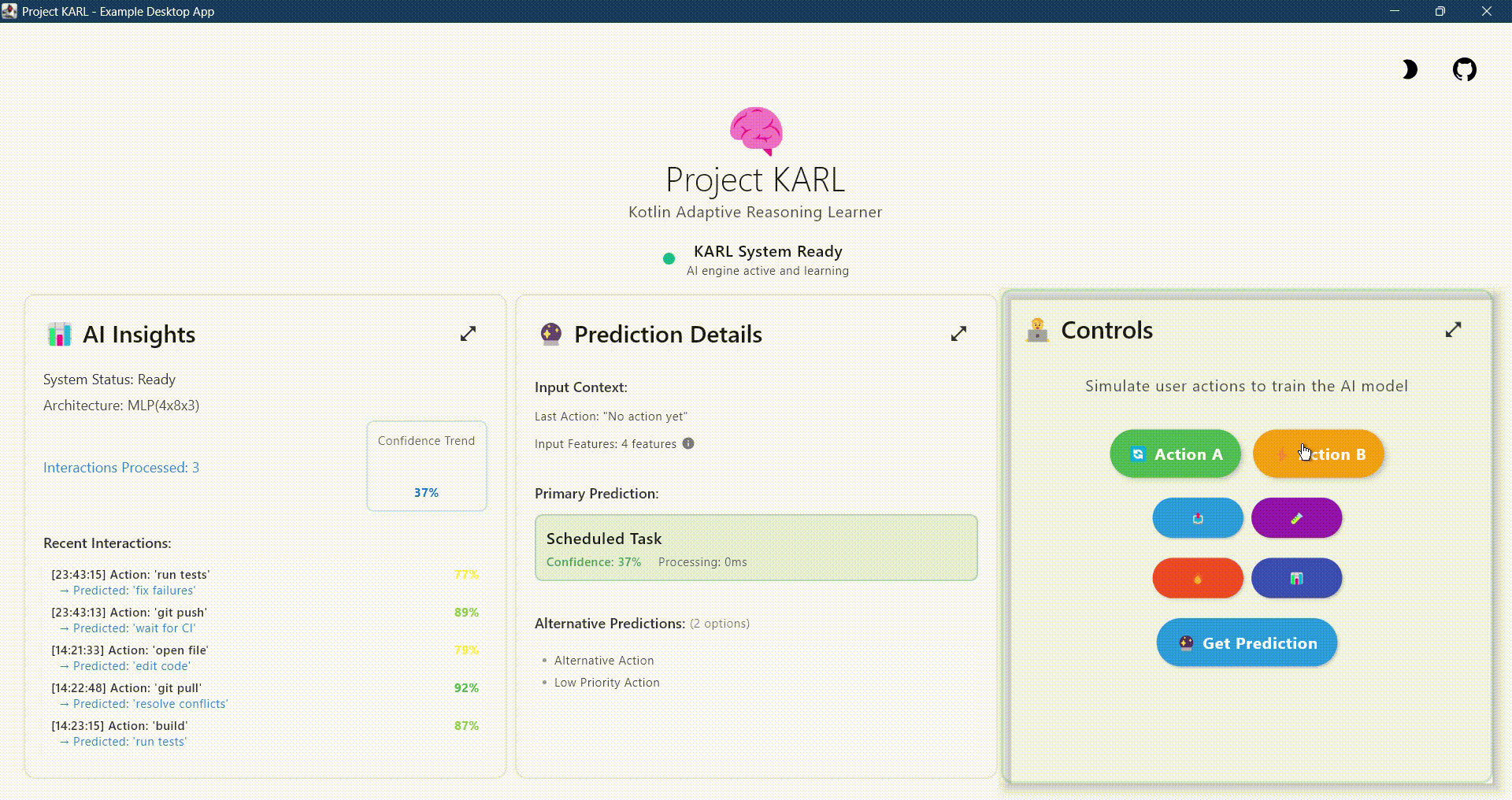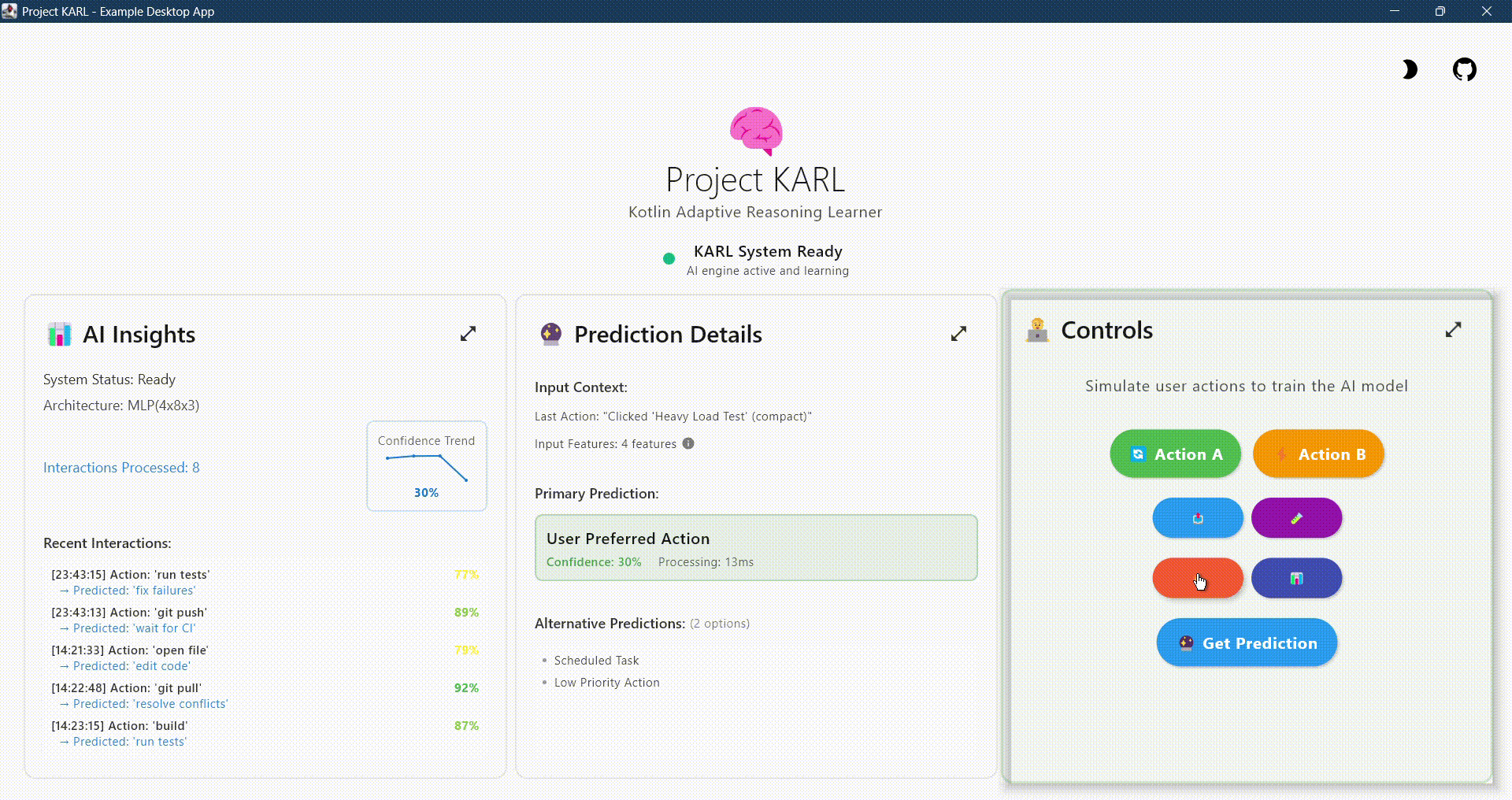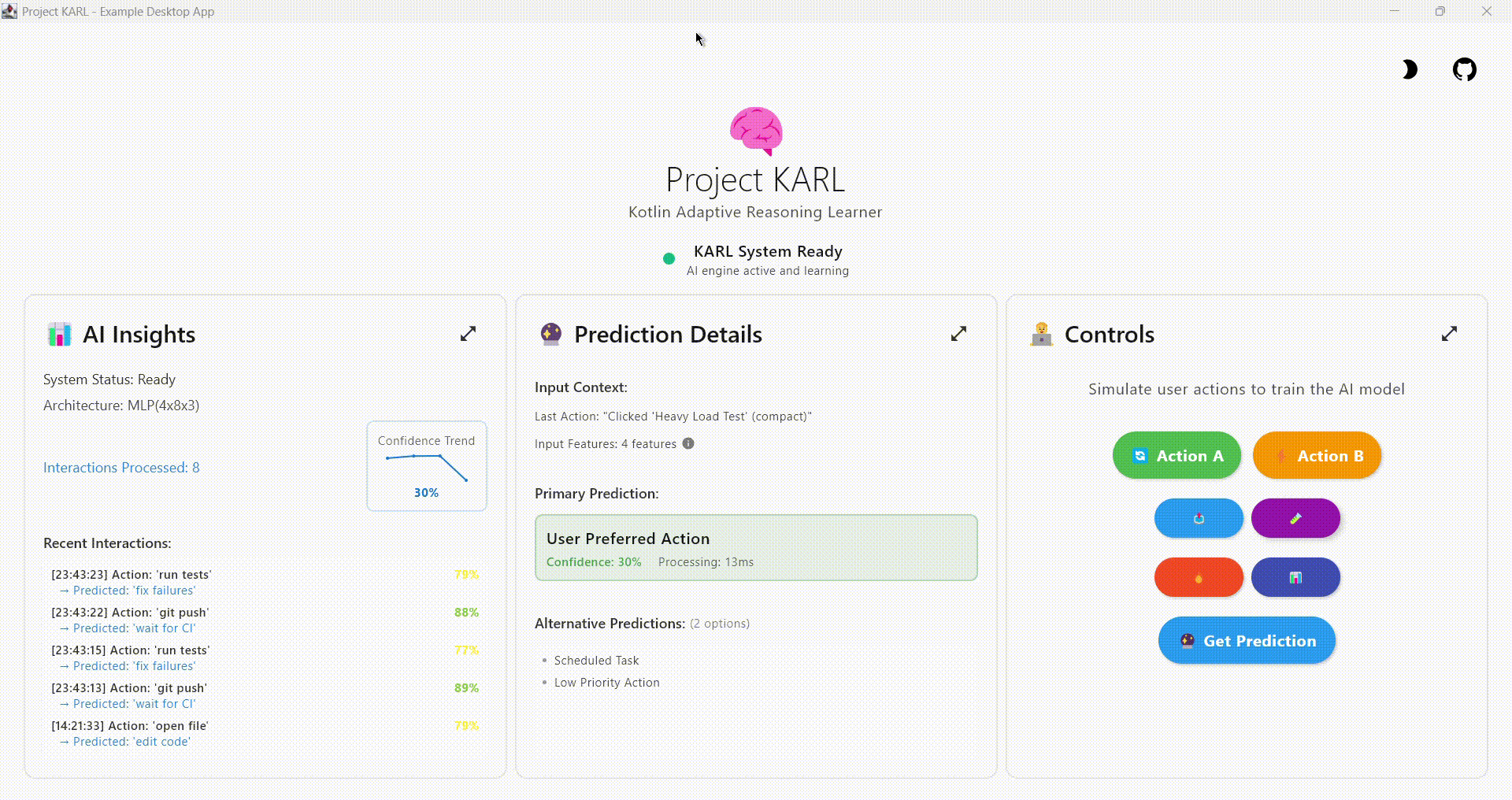
Build intelligent, personalized applications with on-device AI that learns from user behavior while maintaining complete privacy. No cloud required.
🔒 Privacy First
🚀 Kotlin Native
🧠 Adaptive Learning
🧩 Composable Container Architecture
🤝 Open Source
Alpha
Open Source • Apache 2.0 License